🕷some website spider application base on proxy pool (support http & websocket)




| site | document | Last Modified time |
|---|---|---|
| some proxy site,etc. | Proxy pool | 20-06-01 |
| music.163.com | Netease | 18-10-21 |
| - | Press Test System | 18-11-10 |
| news.baidu.com | News | 19-01-25 |
| note.youdao.com | Youdao Note | 20-01-04 |
| jianshu.com/csdn.net | blog | 20-01-04 |
| elective.pku.edu.cn | Brush Class | 19-10-11 |
| zimuzu.tv | zimuzu | 19-04-13 |
| bilibili.com | Bilibili | 20-06-06 |
| exam.shaoq.com | shaoq | 19-03-21 |
| data.eastmoney.com | Eastmoney | 19-03-29 |
| hotel.ctrip.com | Ctrip Hotel Detail | 19-10-11 |
| douban.com | DouBan | 19-05-07 |
| 66ip.cn | 66ip | 19-05-07 |
docker is on the road.
$ git clone https://github.com/iofu728/spider.git$ cd spider$ pip install -r requirement.txt# load proxy pool$ python proxy/getproxy.py # to load proxy resources
To use proxy pool
''' using proxy requests '''from proxy.getproxy import GetFreeProxy # to use proxyproxy_req = GetFreeProxy().proxy_reqproxy_req(url:str, types:int, data=None, test_func=None, header=None)''' using basic requests '''from util.util import basic_reqbasic_req(url: str, types: int, proxies=None, data=None, header=None, need_cookie: bool = False)
.├── LICENSE├── README.md├── bilibili│ ├── analysis.py // data analysis│ ├── bilibili.py // bilibili basic│ └── bsocket.py // bilibili websocket├── blog│ └── titleviews.py // Zhihu && CSDN && jianshu├── brushclass│ └── brushclass.py // PKU elective├── buildmd│ └── buildmd.py // Youdao Note├── eastmoney│ └── eastmoney.py // font analysis├── exam│ ├── shaoq.js // jsdom│ └── shaoq.py // compile js shaoq├── log├── netease│ ├── netease_music_base.py│ ├── netease_music_db.py // Netease Music│ └── table.sql├── news│ └── news.py // Google && Baidu├── press│ └── press.py // Press text├── proxy│ ├── getproxy.py // Proxy pool│ └── table.sql├── requirement.txt├── utils│ ├── db.py│ └── utils.py└── zimuzu└── zimuzu.py // zimuzi
proxy pool is the heart of this project.
Gatherproxy, Goubanjia, xici etc. Free Proxy WebSiteproxy/data/passage one line by username, one line by passwd)from proxy.getproxy import GetFreeProxyproxy_req = GetFreeProxy().proxy_reqproxy_req(url: str, types: int, data=None, test_func=None, header=None)from util import basic_reqbasic_req(url: str, types: int, proxies=None, data=None, header=None)model 1 to download proxy file.Netease Music song playlist crawl - netease/netease_music_db.py
big data storeV2 Proxy IP pool, Record progress, Write to MySQL
Load data/ Replace INTOPress Test System - press/press.py
high concurrency requestsgoogle & baidu info crawl- news/news.py
DOMChinese wordsYoudao Note documents crawl - buildmd/buildmd.py
youdaoyuncsdn && zhihu && jianshu view info crawl - blog/titleview.py
$ python blog/titleviews.py --model=1 >> log 2>&1 # model = 1: load gather model or python blog/titleviews.py --model=1 >> proxy.log 2>&1$ python blog/titleviews.py --model=0 >> log 2>&1 # model = 0: update gather model
PKU Class brush - brushclass/brushclass.py
ZiMuZu download list crawl - zimuzu/zimuzu.py
<Game of Thrones>.Get av data by http - bilibili/bilibili.py
homepage rank -> check tids -> to check data every 2min(during on rank + one day)Get av data by websocket - bilibili/bsocket.py
Get comment data by http - bilibili/bilibili.py
load comment from /x/v2/reply
UnicodeEncodeError: ‘ascii’ codec can’t encode characters in position 7-10: ordinal not in range(128)
utf-8bilibili some url return 404 like http://api.bilibili.com/x/relation/stat?jsonp=jsonp&callback=__jp11&vmid=
basic_req auto add host to headers, but this URL can’t request in ‘Host’
Get text data by compiling javascript - exam/shaoq.py
Idea
Requirement
pip3 install PyExecJSyarn install add jsdom # npm install jsdom PS: not global
Can’t get true html
So you can use threading or await asyncio.gather to request image
Error: Cannot find module ‘jsdom’
jsdom must install in local not in global
remove subtree & edit subtree & re.findall
subtree.extract()subtree.string = new_stringparent_tree.find_all(re.compile('''))
Get stock info by analysis font - eastmoney/eastmoney.py
font analysis
Idea
error: unpack requires a buffer of 20 bytes
requests.content -> byte
How to analysis font
configure file
Get Ctrip Hotel True Detail - ctrip/hotelDetail.py
int32
np.int32()
js charCodeAt() in py
python 中如何实现 js 里的 charCodeAt()方法?
ord(string[index])
python access file fold import
import syssys.path.append(os.getcwd())
generate char list
using ASCII
lower_char = [chr(i) for i in range(97,123)] # a-zupper_char = [chr(i) for i in range(65,91)] # A-Z
Can’t get cookie in document.cookie
Service use HttpOnly in Set-Cookie
The Secure attribute is meant to keep cookie communication limited to encrypted transmission, directing browsers to use cookies only via secure/encrypted connections. However, if a web server sets a cookie with a secure attribute from a non-secure connection, the cookie can still be intercepted when it is sent to the user by man-in-the-middle attacks. Therefore, for maximum security, cookies with the Secure attribute should only be set over a secure connection.
The HttpOnly attribute directs browsers not to expose cookies through channels other than HTTP (and HTTPS) requests. This means that the cookie cannot be accessed via client-side scripting languages (notably JavaScript), and therefore cannot be stolen easily via cross-site scripting (a pervasive attack technique).
ctrip cookie analysis
| key | method | how | constant | login | finish |
|---|---|---|---|---|---|
magicid |
set | https://hotels.ctrip.com/hotel/xxx.html |
1 | 0 | 1 |
ASP.NET_SessionId |
set | https://hotels.ctrip.com/hotel/xxx.html |
1 | 0 | 1 |
clientid |
set | https://hotels.ctrip.com/hotel/xxx.html |
1 | 0 | 1 |
_abtest_userid |
set | https://hotels.ctrip.com/hotel/xxx.html |
1 | 0 | 1 |
hoteluuid |
js | https://hotels.ctrip.com/hotel/xxx.html |
1 | 0 | |
fcerror |
js | https://hotels.ctrip.com/hotel/xxx.html |
1 | 0 | |
_zQdjfing |
js | https://hotels.ctrip.com/hotel/xxx.html |
1 | 0 | |
OID_ForOnlineHotel |
js | https://webresource.c-ctrip.com/ResHotelOnline/R8/search/js.merge/showhotelinformation.js |
1 | 0 | |
_RSG |
req | https://cdid.c-ctrip.com/chloro-device/v2/d |
1 | 0 | |
_RDG |
req | https://cdid.c-ctrip.com/chloro-device/v2/d |
1 | 0 | |
_RGUID |
set | https://cdid.c-ctrip.com/chloro-device/v2/d |
1 | 0 | |
_ga |
js | for google analysis | 1 | 0 | |
_gid |
js | for google analysis | 1 | 0 | |
MKT_Pagesource |
js | https://webresource.c-ctrip.com/ResUnionOnline/R3/float/floating_normal.min.js |
1 | 0 | |
_HGUID |
js | https://hotels.ctrip.com/hotel/xxx.html |
1 | 0 | |
HotelDomesticVisitedHotels1 |
set | https://hotels.ctrip.com/Domestic/tool/AjaxGetHotelAddtionalInfo.ashx |
1 | 0 | |
_RF1 |
req | https://cdid.c-ctrip.com/chloro-device/v2/d |
1 | 0 | |
appFloatCnt |
js | https://webresource.c-ctrip.com/ResUnionOnline/R3/float/floating_normal.min.js?20190428 |
1 | 0 | |
gad_city |
set | https://crm.ws.ctrip.com/Customer-Market-Proxy/AdCallProxyV2.aspx |
1 | 0 | |
login_uid |
set | https://accounts.ctrip.com/ssoproxy/ssoCrossSetCookie |
1 | 1 | |
login_type |
set | https://accounts.ctrip.com/ssoproxy/ssoCrossSetCookie |
1 | 1 | |
cticket |
set | https://accounts.ctrip.com/ssoproxy/ssoCrossSetCookie |
1 | 1 | |
AHeadUserInfo |
set | https://accounts.ctrip.com/ssoproxy/ssoCrossSetCookie |
1 | 1 | |
ticket_ctrip |
set | https://accounts.ctrip.com/ssoproxy/ssoCrossSetCookie |
1 | 1 | |
DUID |
set | https://accounts.ctrip.com/ssoproxy/ssoCrossSetCookie |
1 | 1 | |
IsNonUser |
set | https://accounts.ctrip.com/ssoproxy/ssoCrossSetCookie |
1 | 1 | |
UUID |
req | https://passport.ctrip.com/gateway/api/soa2/12770/setGuestData |
1 | 1 | |
IsPersonalizedLogin |
js | https://webresource.c-ctrip.com/ares2/basebiz/cusersdk/~0.0.8/default/login/1.0.0/loginsdk.min.js |
1 | 1 | |
_bfi |
js | https://webresource.c-ctrip.com/code/ubt/_bfa.min.js?v=20193_28.js |
1 | 0 | |
_jzqco |
js | https://webresource.c-ctrip.com/ResUnionOnline/R1/remarketing/js/mba_ctrip.js |
1 | 0 | |
__zpspc |
js | https://webresource.c-ctrip.com/ResUnionOnline/R1/remarketing/js/s.js |
1 | 0 | |
_bfa |
js | https://webresource.c-ctrip.com/code/ubt/_bfa.min.js?v=20193_28.js |
1 | 0 | |
_bfs |
js | https://webresource.c-ctrip.com/code/ubt/_bfa.min.js?v=20193_28.js |
1 | 0 | |
utc |
js | https://hotels.ctrip.com/hotel/xxx.html |
0 | 0 | 1 |
htltmp |
js | https://hotels.ctrip.com/hotel/xxx.html |
0 | 0 | 1 |
htlstm |
js | https://hotels.ctrip.com/hotel/xxx.html |
0 | 0 | 1 |
arp_scroll_position |
js | https://hotels.ctrip.com/hotel/xxx.html |
0 | 0 | 1 |
some fusion in ctrip
function a31(a233, a23, a94) {var a120 = {KWcVI: "mMa",hqRkQ: function a272(a309, a20) {return a309 + a20;},WILPP: function a69(a242, a488) {return a242(a488);},ydraP: function a293(a338, a255) {return a338 == a255;},ceIER: ";expires=",mDTlQ: function a221(a234, a225) {return a234 + a225;},dnvrD: function a268(a61, a351) {return a61 + a351;},DIGJw: function a368(a62, a223) {return a62 == a223;},pIWEz: function a260(a256, a284) {return a256 + a284;},jXvnT: ";path=/",};if (a120["KWcVI"] !== a120["KWcVI"]) {var a67 = new Date();a67[a845("0x1a", "4Vqw")](a120[a845("0x1b", "RswF")](a67["getDate"](), a94));document[a845("0x1c", "WjvM")] =a120[a845("0x1d", "3082")](a233, "=") +a120[a845("0x1e", "TDHu")](escape, a23) +(a120["ydraP"](a94, null)? "": a120["hqRkQ"](a120["ceIER"], a67[a845("0x1f", "IErH")]())) +a845("0x20", "eHIq");} else {var a148 = a921(this, function() {var a291 = function() {return "dev";},a366 = function() {return "window";};var a198 = function() {var a168 = new RegExp("\\w+ *\\(\\) *{\\w+ *[' | '].+[' | '];? *}");return !a168["test"](a291["toString"]());};var a354 = function() {var a29 = new RegExp("(\\[x|u](\\w){2,4})+");return a29["test"](a366["toString"]());};var a243 = function(a2) {var a315 = ~-0x1 >> (0x1 + (0xff % 0x0));if (a2["indexOf"]("i" === a315)) {a310(a2);}};var a310 = function(a213) {var a200 = ~-0x4 >> (0x1 + (0xff % 0x0));if (a213["indexOf"]((!![] + "")[0x3]) !== a200) {a243(a213);}};if (!a198()) {if (!a354()) {a243("indеxOf");} else {a243("indexOf");}} else {a243("indеxOf");}});// a148();var a169 = new Date();a169["setDate"](a169["getDate"]() + a94);document["cookie"] = a120["mDTlQ"](a120["dnvrD"](a120["dnvrD"](a120["dnvrD"](a233, "="), escape(a23)),a120["DIGJw"](a94, null)? "": a120["pIWEz"](a120["ceIER"], a169["toGMTString"]())),a120["jXvnT"]);}}
equal to
document["cookie"] =a233 +"=" +escape(a23) +(a94 == null ? "" : ";expires=" + a169["toGMTString"]()) +";path=/";
So, It is only a function to set cookie & expires.
And you can think a31 is a entry point to judge where code about compiler cookie.
Get current timezone offset
import datetime, tzlocallocal_tz = tzlocal.get_localzone()timezone_offset = -int(local_tz.utcoffset(datetime.datetime.today()).total_seconds() / 60)
JSON.stringfy(e)
import jsonjson.dumps(e, separators=(',', ':'))
Element.getBoundingClientRect()
return Element position
RuntimeError: dictionary changed size during iteration (when user pickle)
comment_loader = comment.copy()dump_bigger(comment_loader, '{}data.pkl'.format(data_dir))
How to avoid “RuntimeError: dictionary changed size during iteration” error?
pickling SimpleLazyObject fails just after accessing related object of wrapped model instance.
RecursionError: maximum recursion depth exceeded while pickling an object
import syssys.setrecursionlimit(10000)
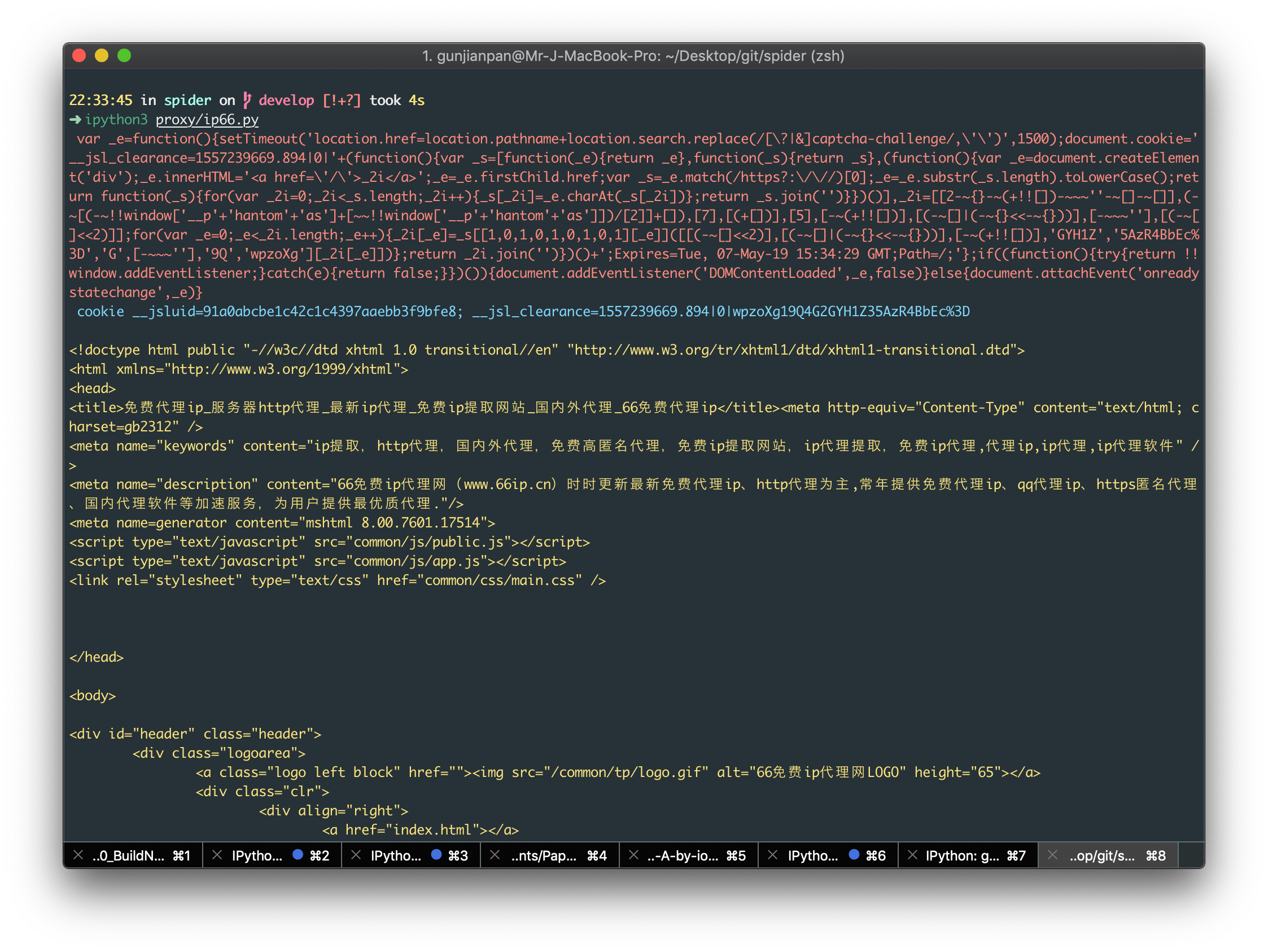
Q: @liu wong 一段 js 代码在浏览器上执行的结果和在 python 上用 execjs 执行的结果不一样,有啥原因呢? http://www.66ip.cn/
A: 一般 eval 差异 主要是有编译环境,DOM,py 与 js 的字符规则,context 等有关
像 66ip 这个网站,主要是从 py 与 js 的字符规则不同 + DOM 入手的,当然它也有可能是无意的(毕竟爬虫工程师用的不只是 py)
首次访问 66ip 这个网站,会返回一个 521 的 response,header 里面塞了一个 HTTP-only 的 cookie,body 里面塞了一个 script
var x = "@...".replace(/@*$/, "").split("@"),y = "...",f = function(x, y) {return num;},z = f(y.match(/\w/g).sort(function(x, y) {return f(x) - f(y);}).pop());while (z++)try {eval(y.replace(/\b\w+\b/g, function(y) {return x[f(y, z) - 1] || "_" + y;}));break;} catch (_) {}
可以看到 eval 的是 y 字符串用 x 数组做了一个字符替换之后的结果,所以按道理应该和编译环境没有关系,但把 eval 改成 aa 之后放在 py 和放在 node,chrome 中编译结果却不一样
这是因为在 p 正则\b 会被转义为\x80,这就会导致正则匹配不到,就更不可能替换了,导致我们拿到的 eval_script 实际上是一串乱码
这里用 r’{}’.format(eval_script) 来防止特殊符号被转义
剩下的就是 对拿到的 eval_script 进行 dom 替换操作
总的来说是一个挺不错的 js 逆向入门练手项目, 代码量不大,逻辑清晰
具体代码参见iofu728/spider
check param list:
| param | Ctrip | Incognito | Node | !!import |
|---|---|---|---|---|
| define | ✔ | x | x | |
| __filename | x | x | x | |
| module | x | x | ✔ | x |
| process | ✔ | x | ✔ | |
| __dirname | ✔ | x | x | |
| global | x | x | ✔ | x |
| INT_MAX | ✔ | x | x | |
| require | ✔ | x | ✔ | ✔ |
| History | ✔ | x | ||
| Location | ✔ | x | ||
| Window | ✔ | x | ||
| Document | ✔ | x | ||
| window | ✔ | x | ||
| navigator | ✔ | x | ||
| history | ✔ | x |
——To be continued——