Automated kubernetes cluster for distributed facial recognition
![]()
![]()
![]()
To deploy:
git clone https://github.com/GHRik/Distributed-k8s-face-recognition.gitcd Distributed-k8s-face-recognition/ansibleansible-playbook -i inventory.yaml main.yaml
Full automatization deploy:
This repo is reworked code from [this repo](https://github.com/Skarlso/kube-cluster-sample) so if you want any info about components or how everything works together , check [this link](https://cheppers.com/deploying-distributed-face-recognition-application-kubernetes)
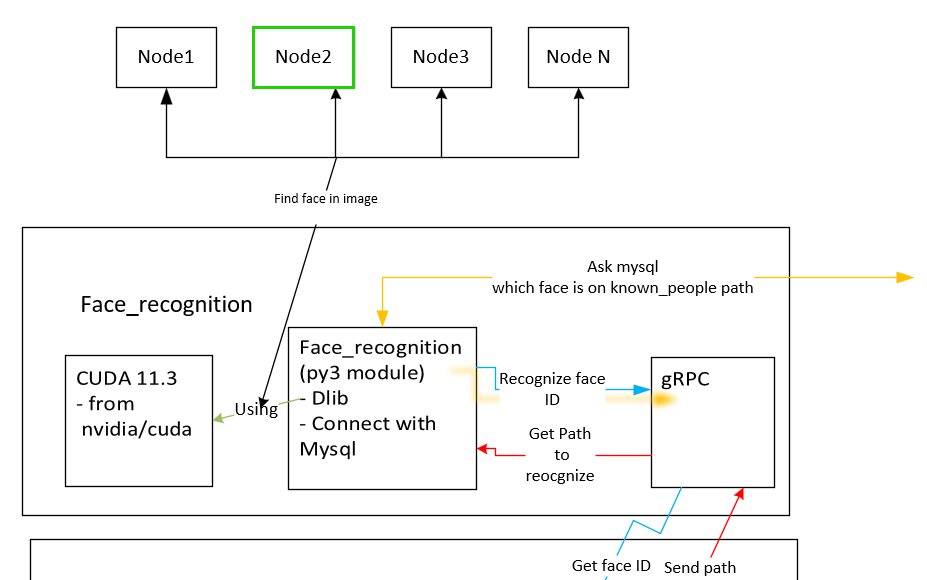
If you still dont know how it works, maybe this diagram will help you ;)
[dlib](http://dlib.net/) have a Pool thread using to find face
To deploy this code you can use ansible tags:
…
No install nvida-docker and kubernetes packages
ansible-playbook -i inventory.yaml main.yaml
…
Have cluster, but dont have deploy cluster face fecogniton from this repo
ansible-playbook -i inventory.yaml main.yaml --tags "deploy"
…
Have cluster, have deployed face recognition from this repo,
but you make changes on kube files or known/unknown people images
ansible-playbook -i inventory.yaml main.yaml --tags "redeploy"
…
Have cluster, this face regoznition deployed, but images not load
or is an error in “recognize” role
ansible-playbook -i inventory.yaml main.yaml --tags "recognize"
…
Have cluster before , have deployed face recognition, but want to recreate cluster
ansible-playbook -i inventory.yaml main.yaml --tags "destroy_cluster"ansible-playbook -i inventory.yaml main.yaml
…
Have deployed face recognition cluster, but want clear it:
ansible-playbook -i inventory.yaml main.yaml --tags: "destroy"
This code support CUDA. In this case if you want deploy this cluster with CUDA support:
Check your GPU - which version CUDA your GPU is using
nvidia-smi
You will see output like this:
+-----------------------------------------------------------------------------+| NVIDIA-SMI 465.19.01 Driver Version: 465.19.01 CUDA Version: 11.3 ||-------------------------------+----------------------+----------------------+| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC || Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. || | | MIG M. ||===============================+======================+======================|| 0 NVIDIA Tesla K80 Off | 00000001:00:00.0 Off | 0 || N/A 34C P8 32W / 149W | 0MiB / 11441MiB | 0% Default || | | N/A |+-------------------------------+----------------------+----------------------++-----------------------------------------------------------------------------+| Processes: || GPU GI CI PID Type Process name GPU Memory || ID ID Usage ||=============================================================================|| No running processes found |+-----------------------------------------------------------------------------+
This cluster was tested uising CUDA 11.3 version, but on my docker hub you can pull other version. Only one pod will be running using CUDA support face_recognition
If you want change a CUDA version, change this line on other version:
face_recognition.yaml30: image: ghrik/face_recognition:cuda11.3
This script using nvida-docker to deploy GPU Scheduling on k8s cluster. In this case you should uninstall your docker if you have.
You can run this cluster without CUDA.
In this case you have to change
face_recognition.yaml30: image: ghrik/face_recognition:1.0
Results are in two pleaces:
Result.txt - If ansible end properly this file will be fill with
the calculated time it takes to recognize a given face
$ cat results/results.txtServer is on: http://10.98.219.249:8081LOGS:Checking image: unknown_people/unknown_02.PNGTime: 0.4799957275390625 sec.Checking image: unknown_people/unknown_03.PNGTime: 0.6136119365692139 sec.Checking image: unknown_people/unknown_04.PNGTime: 0.5596208572387695 sec.Checking image: unknown_people/unknown_01.PNGTime: 0.46269893646240234 sec.
The first line from result.txt is a ip to frontend site.
On this site you will see what faces have been recognized.
As you can see this cluster is checking only faces in ***unknown_people*** dir.
To make your own database with face you change do a small change in
ansible/kube_files/database_setup.sql
So the first step is a create relation people-face
insert into person (name) values('Damian');insert into person (name) values('Barack');insert into person (name) values('Duda');insert into person (name) values('Lewy');
It is very simple, add only something like that
The next step is create relation
picture from known_people - people_id
insert into person_images (image_name, person_id) values ('damian_01.PNG', 1);insert into person_images (image_name, person_id) values ('damian_02.PNG', 1);insert into person_images (image_name, person_id) values ('barack_01.jpg', 2);insert into person_images (image_name, person_id) values ('barack_02.PNG', 2);insert into person_images (image_name, person_id) values ('duda_01.PNG', 3);insert into person_images (image_name, person_id) values ('duda_02.PNG', 3);insert into person_images (image_name, person_id) values ('lewy_01.PNG', 4);insert into person_images (image_name, person_id) values ('lewy_02.PNG', 4);
In any case of error check for the first ***image_processor*** pod
kubectl logs image_processor
List_out_of range
Probably one of images (from ***unknown/known_people)*** does not have any face
to recognize. In this case image_processor cant process this image.
Image_processor is not up
Sometimes a ***image_processor*** must have a more time to get up.
You can see it if you run new cluster. Pulling image to pod can take a long time
No such file or directory on image processor pod
Sometimes ***face_recog_unknown_pvc*** is connected to ***face_recog_known_pv***,
rerun with “redeploy” tag
dont_delete dir in unknown_people
Dont delete ***end.jpg*** , it is corelated with show time all recognized faces.
Sleep 60 in recognize
Sometimes a other services need more time to get up.
To fast deploy you can comment “sleep 60”, and after failed deploy recognize,
rerun with tag: “recognize”
Circuitbreaker is engaged
It means you have more than 5images in ***unknown_people*** dir.
Probably it will unfreeze if not, you can add sleep function in
```sh
ansible/roles/recognize/tasks/main.yaml
40: shell: sleep 10 && curl -d ‘{“path”:”{{ item.path }}”}’ http://{{ receiver_ip.stdout }}:8000/image/post
Or add fewer face pictures ;)- Core dump using without CUDA image <br />***ghrik/face_recognition:1.0*** was builded with AVX acceleration.All of CUDA images is using SSE4 (not AVX)If you want to use dlib without AVX acceleration check flags in dlib section:```shimages/face_recognitionGPU/Dockerfile
and colerate this with
images/face_recognition/Dockerfile
Free to use ;)